Writing
a simple RISC-V emulator in plain C
(Base integer, multiplication
and csr instructions)
Having to study microprocssor architecture and organization, and having implemented a 4 bit CPU in verilog, I wanted to take this up as a personal project, since the open source and modular aspect of RISC-V interested me much. A huge thanks to this riscv emulator in rust book project which helped me tons to understand the implementation of the ISA as per the specifications found on the RISC-V website. This implementation follows the aforementioned book a lot. Here, I have tried to implement the RISC-V ISA and write a fully functional emulator in plain old C. My ultimate goal is to make it run linux for RISC-V and learn about the internal workings of a computer in the process. Until now, I have implemented the Integer, Multiplication and Zicsr modules of the riscv. My next objectives are:
- Privileged Architecture
- Exceptions
- PLIC (a platform-level interrupt controller) and CLINT (a core-local
interrupter)
- UART (a universal asynchronous receiver-transmitter)
- Interrupts
- Virtio
- Virtual Memory System
IMPORTANT!: I wrote this emulator simply for learning purposes, and did not care much about optimization or code quality as long as it works. This blog should in NO WAY be taken as a standard way of writing a riscv implementation and there are many github projects that does so. This blog post was aimed at documenting my steps as I understood the concepts and implemented them, so that I might later use this for a reference, or might be of help to any other beginners. This blog might contain a lot of errors unknown to me, and any correction or modification is welcome and you can contact me by mail regarding this.
What is RISC-V?
A reduced instruction set computer is a computer with a small, highly optimized set of instructions, rather than the more specialized set often found in other types of architecture, such as in a complex instruction set computer (CISC).The main distinguishing feature of RISC architecture is that the instruction set is optimized with a large number of registers and a highly regular instruction pipeline, allowing a low number of clock cycles per instruction (CPI). Core features of a RISC philosophy are a load/store architecture, in which memory is accessed through specific instructions rather than as a part of most instructions in the set, and requiring only single-cycle instructions.
The features that make RISC-V so attractive:
- Fully open source
- Modular
Computer Organization
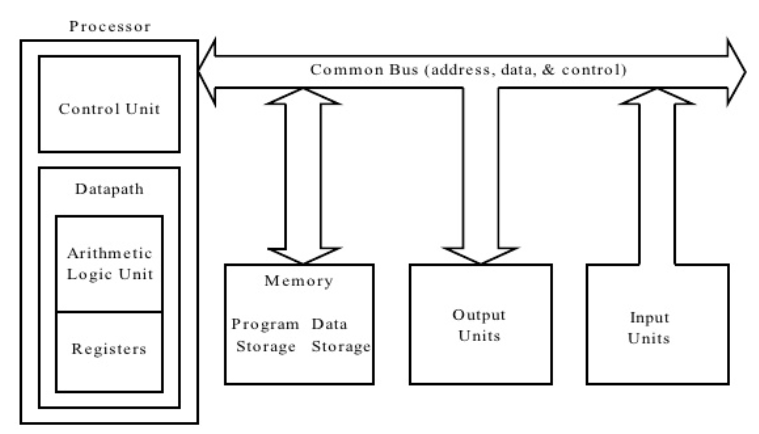
We have the following basic parts of a risc-v cpu:
1. CPU / core
2. DRAM
3. BUS
The bus is the data travel path between the cpu, dram and all other peripheral components. The cpu contains the registers, program counter and the arithmetic logic unit (ALU) that performs all the operations. The following figure depicts the overall structure with the peripheral devices.
inst= mem[PC]
next_PC= PC+ 4
if ( inst.type== STORE) mem[rf[inst.arg1]] = rf[inst.arg2]
if ( inst.type== LOAD) rf[inst.arg1] = mem[rf[inst.arg2]]
if ( inst.type== ALU) rf[inst.arg1] = alu(inst.op, rf[inst.arg2], rf[inst.arg3])
if ( inst.type== COND) next_PC= rf[inst.arg1]
PC= next_PCGetting started
Our emulator will have the following directory structure:
- riscv-emulator/
- src/
- includes/
- main.c
- Makefile
The “includes” folder contains all the header files used, and the
“src” directory contains all the source files corresponding to the
headers. And we have our main.c file that binds everything together.
Installing the riscv-gnu-toolchain
riscv-gnu-toolchain is the RISC-V C and C++ cross-compiler. It supports two build modes: a generic ELF/Newlib toolchain and a more sophisticated Linux-ELF/glibc toolchain.
We will be using this compiler to compile programs written in C for the riscv isa, and generating the binaries for the written C programs for running on the emulator. To install the riscv gnu compiler, install the following prerequisites for your distro
autoconf automake curl python3 mpc mpfr gmp gawk base-devel bison flex texinfo gperf libtool patchutils bc zlib expatAnd then run the following
git clone https://github.com/riscv/riscv-gnu-toolchain
./configure --prefix=/opt/riscv
make && make linuxNow the compilers are located at /opt/riscv/bin. If
/opt/riscv/bin/ is not in your environment PATH, add the
directory to the PATH using
export PATH=$PATH:/opt/riscv/bin/. Now we can compile C
programs for the riscv platform using the following commands.(for the
test file test.c)
# Generate assembly file test.s from test.c
riscv64-unknown-elf-gcc -S test.c
# Generate ELF executable test from test.s
riscv64-unknown-elf-gcc -Wl,-Ttext=0x0 -nostdlib -march=rv64i -mabi=lp64 -o test test.s
# Generate binary file test.bin from ELF file test (what will be read by emulator)
riscv64-unknown-elf-objcopy -O binary test test.binUsing riscv-tests
RISC-V has a github repository riscv-tests, which
contains tests for every instruction for a riscv-core for various
modules. We can check if our implementation of the riscv core works
properly by running these tests. The tests for the different modules are
located in the isa directory. Going over to the rsa
directories, we can build the executables for the required modules, for
example, if we want to test the rv32ui which stands for
rv32 userspace only integer instructions, simply run
cd isa/
make rv32uiWe get all the riscv ELF executables and correspinding dump files containing the instructions executed. Now in our emulator, we read a binary file contents into the memory for execution. In order to convert the ELF executable to binary, we run the following
riscv64-unknown-elf-objcopy -O binary <filename> <filename>.binThis will give us the required binary file for use with our emulator.
Writing a DRAM struct
The DRAM (Dyanmic random access memory) is our memory that contains
all the instructions to be executed and the data. The memory for our
emulator is simply an array of 64-bit variables, to store the 64-bit
values. Here, we define the size of the memory by the variable
DRAM_SIZE and define the start address of the memory in
DRAM_BASE. The memory has a start address higher than 0x0,
because the riscv architecture has a memory mapped I/O.
+---------------+
| Address space |
| +-------+ |
| | ROM | |
| +-------+ |
+-------+address| | | |
| |------>| | RAM | |
| CPU | | | | |
| |<----->| +-------+ |
+-------+ data | | | |
| | I/O | |
| +-------+ |
+---------------+
In memory mapped I/O, as shown in the above figure, the same address space is shared by both the memory and the I/O devices. In a QEMU VM, the lower addresses are used for I/O ports and the DRAM memory starts from the address 0x800000000. So, we use DRAM_BASE=0x80000000. Due to memory mapped I/O, we can perform I/O operations using any instruction that can reference memory. Otherwise, we would have needed seperate instructions and read/write bus for the I/O ports.
So, we write our DRAM struct as follows.
// includes/dram.h
#define DRAM_SIZE 1024*1024*1 // 1 MiB DRAM
#define DRAM_BASE 0x80000000
typedef struct DRAM {
uint8_t mem[DRAM_SIZE]; // Dram memory of DRAM_SIZE
} DRAM;The dram is the memory of the system. The cpu reads data and fetches
instruction from the memory, and also stores/write data to the memory.
So dram has two basic operations, reading from memory and writing from
memory. These 2 functions are defined here as dram_load()
for reading and dram_store() for writing to the memory.
The dram_load() takes the pointer to the dram to be read
from, the address of the data to be read, and the size of the data to be
read, which might be 8, 16, 32 or 64 bits, as per the instruction (LB,
LH, LW, and LD respectively).
For simplicity, for each data size of read, seperate load functions are written, which will then be called from the main load function according to the given size. These are private functions and so not defined in the header, will be implemented in the src file. Thus, our load functions are:
// dram.h
uint64_t dram_load(DRAM* dram, uint64_t addr, uint64_t size);Similar to the load functions, we also write store functions. The
dram_store(), takes the same args as the load functions,
plus the value arg, which contains the data to be written
to the given address of the given dram. Thus, our load functions
are:
// dram.h
void dram_store(DRAM* dram, uint64_t addr, uint64_t size, uint64_t value);DRAM functions
dram_load() and dram_store()
This function takes a DRAM pointer, pointing to the DRAM to load data
from, the address to load data from and the size of the data. Using a
switch statement on the size of the data to be load,
dram_store_8() for 8 bits, and so on. The same goes for the
dram_store() function.
// dram.h
uint64_t dram_load(DRAM* dram, uint64_t addr, uint64_t size) {
switch (size) {
case 8: return dram_load_8(dram, addr); break;
case 16: return dram_load_16(dram, addr); break;
case 32: return dram_load_32(dram, addr); break;
case 64: return dram_load_64(dram, addr); break;
default: ;
}
return 1;
}
void dram_store(DRAM* dram, uint64_t addr, uint64_t size, uint64_t value) {
switch (size) {
case 8: dram_store_8(dram, addr, value); break;
case 16: dram_store_16(dram, addr, value); break;
case 32: dram_store_32(dram, addr, value); break;
case 64: dram_store_64(dram, addr, value); break;
default: ;
}
}Now, we write the functions to load specified number of bits, 8, 16,
32, and 64 from the DRAM. We note here that, due to use of memory mapped
I/O, the address DRAM_BASE corresponds to the memory[0]. So, in order to
access data at given addr, we need to subtract DRAM_BASE
from it. That is the start of the memory is at
mem[addr-DRAM_BASE]
Also, the system we are building is a little endian system, since
most systems today are little endian. Little-endian is an order in which
the “little end” (least significant value in the sequence) is stored
first, that is the least significant bytes are stored in the lower
addresses. So while loading, we read the lower address values first into
the bus by returning, and then, left shifting by 8 bits (1 byte) and AND
with 0xff(8 1s) to get the lower byte only and clear all the higher
bytes while ORing, load the next address into higher places, as per the
required size. The implementation of dram_load_32 and
dram_load_64 are shown below. These functions should be
defined before the dram_load() and
dram_store() functions.
// dram.c
uint64_t dram_load_32(DRAM* dram, uint64_t addr){
return (uint64_t) dram->mem[addr-DRAM_BASE]
| (uint64_t) dram->mem[addr-DRAM_BASE + 1] << 8
| (uint64_t) dram->mem[addr-DRAM_BASE + 2] << 16
| (uint64_t) dram->mem[addr-DRAM_BASE + 3] << 24;
}
uint64_t dram_load_64(DRAM* dram, uint64_t addr){
return (uint64_t) dram->mem[addr-DRAM_BASE]
| (uint64_t) dram->mem[addr-DRAM_BASE + 1] << 8
| (uint64_t) dram->mem[addr-DRAM_BASE + 2] << 16
| (uint64_t) dram->mem[addr-DRAM_BASE + 3] << 24
| (uint64_t) dram->mem[addr-DRAM_BASE + 4] << 32
| (uint64_t) dram->mem[addr-DRAM_BASE + 5] << 40
| (uint64_t) dram->mem[addr-DRAM_BASE + 6] << 48
| (uint64_t) dram->mem[addr-DRAM_BASE + 7] << 56;
}We write similar functions for the load_store functions. Since they
write to the memory, they don’t return anything. And being little
endian, we store the least significant byte first, then right shift by a
byte to store the higher bytes. dram_store_16 and
dram_store_64 are shown below.
// dram.c
void dram_store_16(DRAM* dram, uint64_t addr, uint64_t value) {
dram->mem[addr-DRAM_BASE] = (uint8_t) (value & 0xff);
dram->mem[addr-DRAM_BASE+1] = (uint8_t) ((value >> 8) & 0xff);
}
void dram_store_64(DRAM* dram, uint64_t addr, uint64_t value) {
dram->mem[addr-DRAM_BASE] = (uint8_t) (value & 0xff);
dram->mem[addr-DRAM_BASE + 1] = (uint8_t) ((value >> 8) & 0xff);
dram->mem[addr-DRAM_BASE + 2] = (uint8_t) ((value >> 16) & 0xff);
dram->mem[addr-DRAM_BASE + 3] = (uint8_t) ((value >> 24) & 0xff);
dram->mem[addr-DRAM_BASE + 4] = (uint8_t) ((value >> 32) & 0xff);
dram->mem[addr-DRAM_BASE + 5] = (uint8_t) ((value >> 40) & 0xff);
dram->mem[addr-DRAM_BASE + 6] = (uint8_t) ((value >> 48) & 0xff);
dram->mem[addr-DRAM_BASE + 7] = (uint8_t) ((value >> 56) & 0xff);
}The full dram.c file can be found here
Writing a BUS struct
A bus simply provides a path for data transfer across the various components of a computer. For our riscv emulator, the address bus and data bus is a single 64-bit wide bus (for 64 bit implementation). The bus, in our case, connects the CPU and the DRAM. So we write a BUS struct, with a DRAM object, to which it is connected to.
// includes/bus.h
typedef struct BUS {
struct DRAM dram;
} BUS;We also define two functions bus_load() and
bus_store() which loads and stores values respectively to
or from the provided address in the DRAM connected to the bus, a pointer
to which is provided as function arg.
// includes/bus.h
uint64_t bus_load(BUS* bus, uint64_t addr, uint64_t size);
void bus_store(BUS* bus, uint64_t addr, uint64_t size, uint64_t value);BUS functions
The bus functions simply load and store data from and to the dram
using the public functions dram_load() and
dram_store() functions respectively. The functions are
implemented as follows.
// bus.c
uint64_t bus_load(BUS* bus, uint64_t addr, uint64_t size) {
return dram_load(&(bus->dram), addr, size);
}
void bus_store(BUS* bus, uint64_t addr, uint64_t size, uint64_t value) {
dram_store(&(bus->dram), addr, size, value);
}Writing a basic CPU struct
Firstly, we write a cpu struct with all the components contained by the cpu,
- Registers: The risc-v cpu has 32 registers each 64 bit wide (since
we are implementing a 64 bit core). The register x0 is hardwired to 0,
and the rest are used for storing values.
- There is another unprivileged register
pcwhich is the program counter. This register holds the address of the current instruction being executed.
- And we have a
busthat connects our cpu to the system bus, for reading and writing data from and to the memory (DRAM) respectively.
So, our cpu struct CPU is written as follows. We write
the struct definition in the includes/cpu.h file.
// includes/cpu.h
#include <stdint.h>
typedef struct CPU {
uint64_t regs[32]; // 32 64-bit registers (x0-x31)
uint64_t pc; // 64-bit program counter
struct BUS bus; // CPU connected to BUS
} CPU;Having written the struct, we need to write functions for each of tasks of cpu pipeline. We define the following functions
// includes/cpu.h
void cpu_init(struct CPU *cpu);
uint32_t cpu_fetch(struct CPU *cpu);
int cpu_execute(struct CPU *cpu, uint32_t inst);
void dump_registers(struct CPU *cpu);The
cpu_initfunction initializes the provided cpu by pointer by 0 initializing all the 32 registers, and setting the program counterpcto the start of the memory.The
cpu_fetchfunction reads instructions from the memory (DRAM) for execution, and stores it to the instruction variableinst.cpu_executeis basically the ALU and the instruction decoder combined. It decodes the instruction fetched from the DRAM in theinstvariable and executes the instruction accordingly.dump_registeris just a debug function to view the contents of the 32 registers when needed.
CPU Functions
Now, we write the cpu functions as defined in the header file in the
file src/cpu.c.
cpu_init()
First, we write the cpu_init function. This function
zero initializes all the 32 64-bit registers. The register x02, contains
the stack pointer SP, which should point to the top of the memory. So
x02 should be equal to the the DRAM_SIZE plus the base address from
which the memory starts, DRAM_BASE. So, x02=DRAM_SIZE+DRAM_BASE. And
finally, the program counter should point to the start of the memory
which contains the first instruction. So, pc=DRAM_BASE.
// cpu.c
void cpu_init(CPU *cpu) {
cpu->regs[0] = 0x00; // register x0 hardwired to 0
cpu->regs[2] = DRAM_BASE + DRAM_SIZE; // Set stack pointer
cpu->pc = DRAM_BASE; // Set program counter to the base address
}cpu_fetch()
Now, we write the cpu_fetch(). This instruction fetches
the instruction data at the program counter address from the dram. The
data is put on the bus from the dram using the dram_load()
function where we load the data at the address given by the
pc which points to the instruction to be read. So our
function can be written as follows.
// cpu.c
uint32_t cpu_fetch(CPU *cpu) {
uint32_t inst = bus_load(&(cpu->bus), cpu->pc, 32);
return inst;
}Private load/store functions
We write two private functions cpu_load() and
cpu_store() functions for loading and storing data. These
functions just use the bus load/store functions to read/write data
from/to the dram.
// cpu.c
uint64_t cpu_load(CPU* cpu, uint64_t addr, uint64_t size) {
return bus_load(&(cpu->bus), addr, size);
}
void cpu_store(CPU* cpu, uint64_t addr, uint64_t size, uint64_t value) {
bus_store(&(cpu->bus), addr, size, value);
}Instruction decoding
The instruction that we read from the dram for executeion is 32-bit wide. These 32 bits contain all the directives for the operation to perform, like the opcode which defines the operation to perform, the source and destination registers to read/write from/to, the immediate value and so on. The decoding will be different for different types of instructions which are categorized into the following:
- R-Type: Register type instructions
- I-Type: Immediate type instructions
- S-Type: Store type instructions
- B-Type: Break type instructions
- U-Type: Register type instructions
- J-Type: Jump type instructions
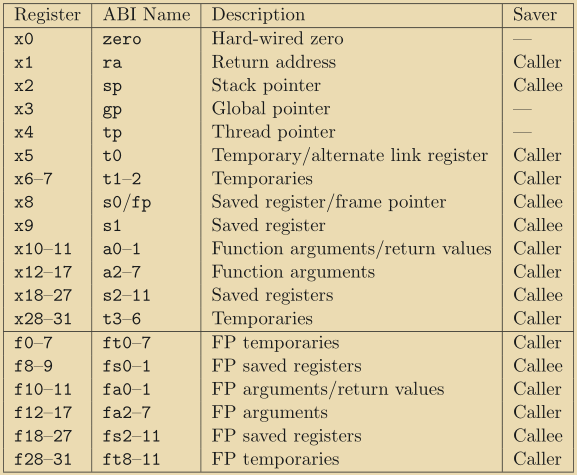
The following table shows the map for the registers for the different types of instructions.

Here, the annontations are:
- opcode
- Lower 7 bit (inst[6:0]) specifies the code for each cpu operation
- rd
- A 4 bit value (inst[11:7]) which gives the address of destination register
- funct3
- A 3 bit value (inst[14:12]). The opcode is the same for a group of similar category operations e.g. (ADD, SUB, DIV, MUL, etc.). In such cases, the group can contain upto 8 different instructions for 8 values of funct3.
- funct7
- A 7 bit value (inst[31:25]). Just like funct3, funct7 divides a group of same funct3 instructions into multiple instructions. For example, SR(shift right) has 2 instuctions: SRA (arithmetic shift) and SRL (logical shift) for different funct7
- rs1
- A 4 bit value (inst[19:15]) which gives the address of source register 1
- rs2
- A 4 bit value (inst[24:20]) which gives the address of source register 2
- imm
- A value which gives the address of destination register
- shamt
- shamt is located in the lower bits of imm and stores the shift amount for shift instructions
We write functions for decoding each part of the 32 bit instruction
mentioned above. The decoding structure varies according to the
different types of instruction. The one that we need to take care of in
such case is the imm, which is the immediate value. The
rest of the blocks can be decoded using a common function for all the
five blocks. Following the instruction map given above, we write the
following functions for decoding each block. Necessary comments have
been added to understand the positioning of the blocks in the
instruction.
// cpu.c
uint64_t rd(uint32_t inst) {
return (inst >> 7) & 0x1f; // rd in bits 11..7
}
uint64_t rs1(uint32_t inst) {
return (inst >> 15) & 0x1f; // rs1 in bits 19..15
}
uint64_t rs2(uint32_t inst) {
return (inst >> 20) & 0x1f; // rs2 in bits 24..20
}
uint64_t imm_I(uint32_t inst) {
// imm[11:0] = inst[31:20]
return ((int64_t)(int32_t) (inst & 0xfff00000)) >> 20;
}
uint64_t imm_S(uint32_t inst) {
// imm[11:5] = inst[31:25], imm[4:0] = inst[11:7]
return ((int64_t)(int32_t)(inst & 0xfe000000) >> 20)
| ((inst >> 7) & 0x1f);
}
uint64_t imm_B(uint32_t inst) {
// imm[12|10:5|4:1|11] = inst[31|30:25|11:8|7]
return ((int64_t)(int32_t)(inst & 0x80000000) >> 19)
| ((inst & 0x80) << 4) // imm[11]
| ((inst >> 20) & 0x7e0) // imm[10:5]
| ((inst >> 7) & 0x1e); // imm[4:1]
}
uint64_t imm_U(uint32_t inst) {
// imm[31:12] = inst[31:12]
return (int64_t)(int32_t)(inst & 0xfffff999);
}
uint64_t imm_J(uint32_t inst) {
// imm[20|10:1|11|19:12] = inst[31|30:21|20|19:12]
return (uint64_t)((int64_t)(int32_t)(inst & 0x80000000) >> 11)
| (inst & 0xff000) // imm[19:12]
| ((inst >> 9) & 0x800) // imm[11]
| ((inst >> 20) & 0x7fe); // imm[10:1]
}
uint32_t shamt(uint32_t inst) {
// shamt(shift amount) only required for immediate shift instructions
// shamt[4:5] = imm[5:0]
return (uint32_t) (imm_I(inst) & 0x1f); // TODO: 0x1f / 0x3f ?
}
cpu_execute()
Now that we have decoded our instruction, we can execute the
instructions as per the decoded data. The opcodes tell us what operation
to perform with the provided data and registers. What exact operation we
should perform, depends on 3 values, the opcode, funct3 and funct6. As
per the map of the instruction, we decode these 3 using the following in
the cpu_execute function.
// cpu.c
int cpu_execute(CPU *cpu, uint32_t inst) {
int opcode = inst & 0x7f; // opcode in bits 6..0
int funct3 = (inst >> 12) & 0x7; // funct3 in bits 14..12
int funct7 = (inst >> 25) & 0x7f; // funct7 in bits 31..25
cpu->regs[0] = 0; // x0 hardwired to 0 at each cycleHere, since the register x0 is hardwired to 0, we have to manually set it to 0 at each cpu cycle, since the emualtor does not have any real 0 (GND) to tie to
Now, that we have our opcode, we can start executing instructions accrodingly. The instruction set table for the different modules are given in the riscv specifications book. According to the table, we check our opcodes using a switch to find which operation to perform and execute that operation on the given resiters or immediates. For example, the table for the simple arithmetic and logical oprations like ADDI, ORI, ANDI, which operates with the given immediate value is:

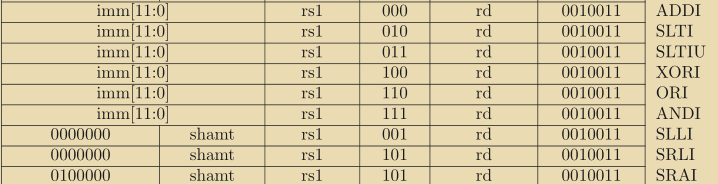
Here, we see, the opcode for these I-Type instructions are 0010011.
Now dealing with such binaries for the case statements makes the code
un-understandable. So, we define the opcodes and the respective
operation names in an opocodes.h file in our “includes/”
folder. For the I-type instructions, we can define the opcodes as
follows using the hex codes of the given binaries.
// opcodes.h
#define I_TYPE 0x13
#define ADDI 0x0
#define SLLI 0x1
#define SLTI 0x2
#define SLTIU 0x3
#define XORI 0x4
#define SRI 0x5
#define SRLI 0x00
#define SRAI 0x20
#define ORI 0x6
#define ANDI 0x7Here, we see, for the same opcode 0x13 we have different
operations based on funct3. Again, for the same funct3
0x5 we have two operations as per different values of
funct7.
Now, for these I-Type instructions, we can write our switch statement as follows.
// cpu.c
switch (opcode) {
case I_TYPE:
switch (funct3) {
case ADDI: exec_ADDI(cpu, inst); break;
case SLLI: exec_SLLI(cpu, inst); break;
case SLTI: exec_SLTI(cpu, inst); break;
case SLTIU: exec_SLTIU(cpu, inst); break;
case XORI: exec_XORI(cpu, inst); break;
case SRI:
switch (funct7) {
case SRLI: exec_SRLI(cpu, inst); break;
case SRAI: exec_SRAI(cpu, inst); break;
default: ;
} break;
case ORI: exec_ORI(cpu, inst); break;
case ANDI: exec_ANDI(cpu, inst); break;
default: ;
} break;
default:
fprintf(stderr,
"[-] ERROR-> opcode:0x%x, funct3:0x%x, funct3:0x%x\n"
, opcode, funct3, funct7);
return 0;
/*exit(1);*/
}For each of the operations, we will be writing a
exec_<op-name>function which takes the cpu pointer and the instruction as args.
Here, in case we have a wrong opcode, or if the operation is not implmented yet, we print to stderr with the opcode that failed as defalut.
Now, we write the exec functions for each of the
operations. What each operation does has been well explained in the
RISC-V specs. The executions were written following those.
While writing the exec functions, care should be taken regarding which parts will be sign extended or zero extended. For example, imm is often sign-extended to 64-bits before being operated on with other values in registers. We can sign extend in C by typecasting by the serial (int32_t) > (int64_t) > (uint_64t), when needed.
// cpu.c
void exec_ADDI(CPU* cpu, uint32_t inst) {
uint64_t imm = imm_I(inst);
cpu->regs[rd(inst)] = cpu->regs[rs1(inst)] + (int64_t) imm;
print_op("addi\n");
}
void exec_SLTI(CPU* cpu, uint32_t inst) {
uint64_t imm = imm_I(inst);
cpu->regs[rd(inst)] = (cpu->regs[rs1(inst)] < (int64_t) imm)?1:0;
print_op("slti\n");
}
void exec_SRAI(CPU* cpu, uint32_t inst) {
uint64_t imm = imm_I(inst);
cpu->regs[rd(inst)] = (int32_t)cpu->regs[rs1(inst)] >> imm;
print_op("srai\n");
}Following the RISC-V specs book, we write down all the rest of the
opcodes in the opcodes.h file, include their cases in the
switch statement and write their execution functions. All of the
operations are pretty basic and easy to get. The ones I had some
difficutly understanding are:
LUI
AUIPC
The main file
Now, we connect all the structs and functions written in the
main.c file, which will run our emulator loop, taking the
binary file as the input.
Firstly, we need to read the contents of the input binary file into
the memory. The filename for the binary file is taken input as a command
line arg. Then, in order to read the contents of the file byte by byte,
we write the following read_file function, which takes the
cpu and the provided binary filename as args.
The function reads the binary contents of the file, and writes them to
the DRAM memory of the provided CPU pointer.
// main.c
void read_file(CPU* cpu, char *filename)
{
FILE *file;
uint8_t *buffer;
unsigned long fileLen;
//Open file
file = fopen(filename, "rb");
if (!file) {
fprintf(stderr, "Unable to open file %s", filename);
}
//Get file length
fseek(file, 0, SEEK_END);
fileLen=ftell(file);
fseek(file, 0, SEEK_SET);
//Allocate memory
buffer=(uint8_t *)malloc(fileLen+1);
if (!buffer) {
fprintf(stderr, "Memory error!");
fclose(file);
}
//Read file contents into buffer
fread(buffer, fileLen, 1, file);
fclose(file);
// Print file contents in hex
for (int i=0; i<fileLen; i+=2) {
if (i%16==0) printf("\n%.8x: ", i);
printf("%02x%02x ", *(buffer+i), *(buffer+i+1));
}
printf("\n");
// copy the bin executable to dram
memcpy(cpu->bus.dram.mem, buffer, fileLen*sizeof(uint8_t));
free(buffer);
}Now, we write the main function. First we create a new cpu of type
struct CPU. We initialize the cpu using
cpu_init(), then use the read_file() function
to read the contents of the binary file to the DRAM memory.
The next part performs the cpu fetch and execution loop. In this implementation, we have a 3 stage instruction pipeline to execute all the instructions. These are:
- Stage 1 (fetch Instruction): Here, the cpu reads
the instruction from the address (stored in the program counter pc) of
the DRAM.
- Stage 2 (Instruction Decode): Here, the fetched
instruction is decoded to get the opcode, destination and source
registers, etc.
- Stage 3 (Instruction Execute): Here, the instruction is executed following the decoded bits, in the ALU.
The stage 1 is handled by the cpu_fetch() function and
the stages 2 and 3 are handled together in the
cpu_execute() function defined in the cpu.h
file. The program counter, pc, is incremented by 4 bytes(32 bits, since
each instruction is 32 bit wide for riscv) at each loop, to get the next
instruction from the memory. Thus our cpu processing loop can be written
as follows.
// main.c
// Initialize cpu, registers and program counter
struct CPU cpu;
cpu_init(&cpu);
// Read input file
read_file(&cpu, argv[1]);
// cpu loop
while (1) {
// fetch
uint32_t inst = cpu_fetch(&cpu);
// Increment the program counter
cpu.pc += 4;
// execute
if (!cpu_execute(&cpu, inst))
break;
dump_registers(&cpu);
if(cpu.pc==0)
break;
}
return 0;
}